


La Découverte de DuckDB et MotherDuck
#4 Traitement de la données en mémoire

Avant de commencer, je tiens à te remercier, toi qui me lis. Nous sommes presque 100 après 3 semaines, vivement la suite ❤️
Mercredi dernier, j'ai pu participer à un Meetup organisé par MotherDuck avec la découverte de 3 cas d’usages intéressants.
Une rencontre enrichissante pour toute personne travaillant sur DBT ou Snowflakes et souhaitant optimiser les coûts pour l’exploration de données.

DuckDB vs. MotherDuck: Quelle Différence?
Pour ceux qui découvrent le concept, DuckDB est un système de gestion de bases de données relationnelles (SGBDR) conçu pour optimiser la lecture de données (voir ce post pour mieux comprendre). Contrairement aux systèmes traditionnels, DuckDB fonctionne en utilisant la mémoire de votre ordinateur sans nécessiter une architecture client-serveur.


Ce choix technique offre l'avantage considérable de pouvoir connecter DuckDB à des outils de la moderne data stack comme DBT ou Snowflake sans avoir à recourir à l’utilisation des serveurs sur le cloud, offrant ainsi une possibilité d’économie non négligeable :)
Mais alors, où intervient MotherDuck dans cette équation?
MotherDuck est une plateforme qui permet d'exploiter DuckDB dans le cloud, sur des serveurs distribués, en ajoutant une couche de fonctionnalités cruciales pour les équipes de données. Avec MotherDuck, tu bénéficies:
➡️ du partage de bases de données
➡️ d'un IDE SQL intégré pour des analyses interactives
➡️ d'un stockage persistant
➡️ d'une exécution hybride des données
➡️ d'une gestion sécurisée des secrets, comme les identifiants AWS S3.
Les Pépites du Meetup
Le meetup a été l'occasion de présenter des use cases de DuckDB et MotherDuck à travers 3 articles de blog.
La Fédération de Tables avec DuckDB : Cette approche permet de travailler efficacement sur plusieurs tables gérées par différents SGBDR, en tirant parti des performances de DuckDB et de fonctionnalités SQL avancées. Des exemples incluent les mots clefs
EXCLUDE,REPLACE,QUALIFYetGROUP BY ALL. J’ai écris un post Linkedin sur le sujet.
L’article complet sur la fédération de données.
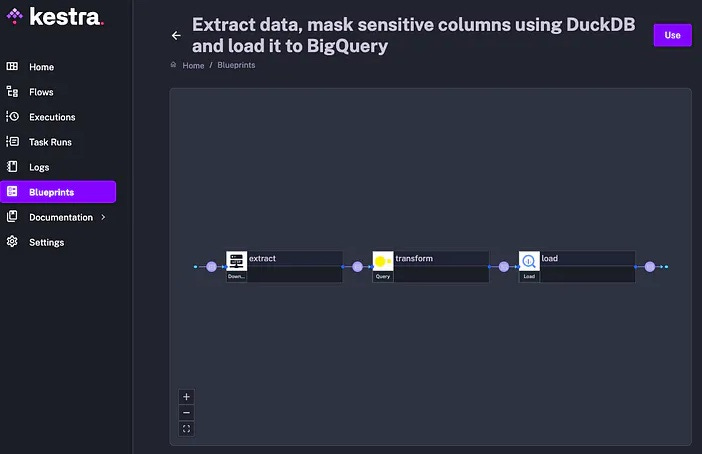
Lire de la donnée provenant à la fois de MySQL et de S3 MotherDuck Couplé à Kestra : L'outil d'orchestration Kestra, combiné à MotherDuck, facilite la création de pipelines ETL (Extract, Transform, Load) et de rapports avec données sensibles. Cette intégration souligne l'importance des outils d'orchestration dans l'automatisation des workflows de données.
Pour plus d’information, voici l’article complet.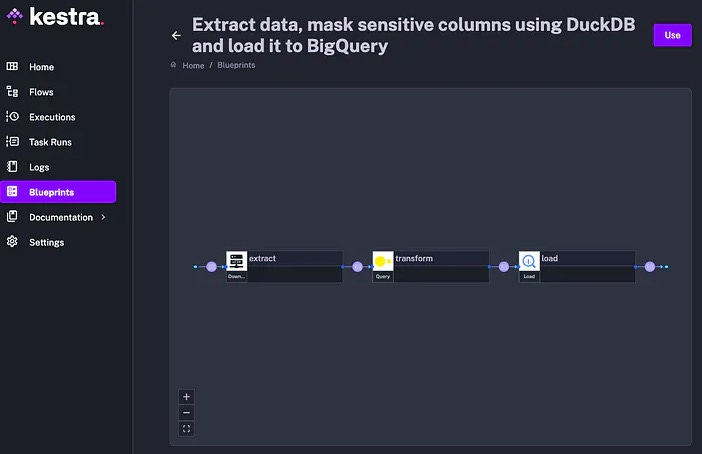
Insérer MotherDuck pour transformer la donnée dans les processus ETL DuckDB chez Hugging Face : Cette présentation a illustré comment DuckDB contribue à rendre le Generative AI plus accessible chez Hugging Face, en permettant la transformation de données et leur visualisation directement sur le web, grâce à des outils comme Rill.
Un article sur DuckDB et les outils de visualisation.
DuckDB permet la transformation de données sur la page internet directement (côté client) sans surcharger le serveur


C'est tout pour cette semaine, mais l'aventure continue. La semaine prochaine un nouveau meetup avec 3 auteurs à succès dans le monde de la data:

Hala Nelson, auteure de "Essential Math for AI", présentera quatre parcours distincts pour travailler dans le domaine de l'intelligence artificielle. Elle détaillera également les compétences, les stratégies, les niveaux de maîtrise et les besoins en financement et en investissement nécessaires pour chacun de ces parcours.
Joe Reis, auteur de "Fundamentals of Data Engineering", nous livrera sa vision de la modélisation des données et ce qu'elle représente réellement.
Ole Olesen-Bagneux, auteur de "The Enterprise Data Catalog", abordera la question des métadonnées en lien avec les pipelines de données.
Si tu veux t’inscrire le lien est ici.
