


Base de données orientée colonnes ou lignes?
#2 Pour les Data Analysts....colonne!

Avant de commencer, je tiens à te remercier toi qui me lis. On est déjà 50 après une semaine, je ne pensais pas pouvoir attirer autant de monde aussi vite ❤️.
Lorsque tu passes une commande sur Amazon : les informations de ta commande, comme l'heure, le numéro de commande et les produits achetés, sont stockées dans une base de données orientée lignes.
Mais pour analyser ces informations et obtenir des insights, par exemple identifier les produits les plus vendus dans chaque catégorie alors des bases de données orientées colonnes sont utilisées.

Quelle est la différence entre ces 2 systèmes de stockage?
La table apparaît de la même manière dans les 2 systèmes de stockage mais la structure utilisée aura un impact significatif sur la façon dont les données seront écrites et lues.
Les bases de données orientées lignes organisent le stockage de données par ligne, ce qui est idéal pour l'écriture et la mise à jour d'informations. En revanche, les bases de données orientées colonnes regroupent les données par type, ce qui facilite l'analyse et l'agrégation.
Prenons l’exemple d’une table de commandes
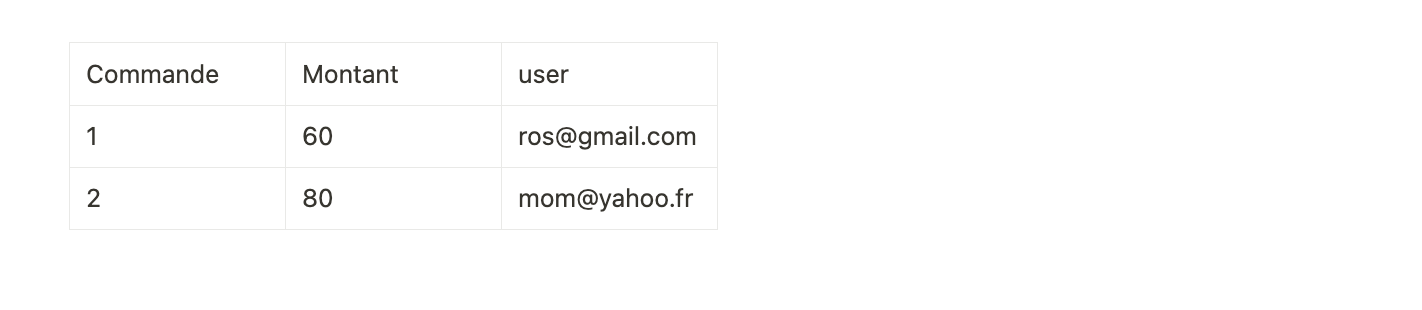
Stockage orienté lignes
Si on utilise un système de gestion de base de données relationnelles orienté lignes comme PostgreSQL ou MySQL, la donnée sera organisée de la manière suivante:

Imaginons que le user ros@gmail.com effectue une nouvelle commande, la table sera mise à jour de la manière suivante:

La nouvelle ligne va être stockée à la suite de l’élément le plus à droite de la dernière ligne, ici mom@yahoo.fr

Ainsi, l'ajout de nouvelles données est donc très simple et rapide.
En revanche, l'analyse de données est plus complexe. Pour calculer le montant moyen d'une commande, il faut charger l'ensemble des données en mémoire et ensuite extraire uniquement les données relatives aux montants.
En conséquence, de nombreuses données sont traitées inutilement, ce qui entraîne une diminution des performances pour la lecture des données.
Stockage orienté colonne
Maintenant, si on utilise des systèmes de gestion de base de données relationnelles orienté colonnes comme BigQuery ou Snowflake, alors la donnée de la table commande (avant la mise à jour) sera stockée par colonne. En premier, il y aura tous les identifiants des commandes (1 et 2), puis les montants suivis des emails.

Après la mise à jour, les données seront donc stockées de la manière suivante:

Comme tu peux le constater, l'écriture de nouvelles données est plus complexe que dans les bases de données orientées lignes car elle nécessite de déplacer plusieurs blocs de données. Cette opération demandera plus de mémoires que dans une base de données orientée lignes.
En revanche, la lecture des données est beaucoup plus simple. Pour calculer le montant moyen d'une commande, il suffit de sélectionner les données correspondantes aux montants. Ici toutes les données entre la 4ème valeur → 60 et la 6ème valeur → 70.
Pour Data Analyst ou un Data Scientist qui doit principalement lire des données via des requêtes de type SELECT, tu comprends qu’utiliser une base de données orientée colonnes est bien plus pratique 😊
Cet exemple est simplifié à des fins de compréhension mais pour aller plus loin, je te recommande l’article "C-Store: A Column-oriented DBMS".
3 points clés à retenir
Écriture optimisée avec les bases de données orientées lignes : Idéales pour les transactions et l'enregistrement rapide de nouvelles données.
Analyse améliorée avec les bases de données orientées colonnes : Permettent une récupération et une analyse de données plus rapides pour des insights précis.
Choix influencé par la performance : La différence de stockage (lignes vs colonnes) détermine avec un impact direct sur l'écriture et l'analyse des données.
La nouvelle de la semaine
Cette semaine est sortie mon QueryBook, un livre pour maitriser l’écriture de requête en SQL. Le Système de gestion de base de données utilisé est DuckDB qui travaille avec des bases de données orientées…..colonnes :)
Le lien ici pour accéder aux premières pages du QueryBook.
Evènement à ne pas manquer sur Paris

MotherDuck (l’entreprise qui se concentre sur le développement et le support de DuckDB) en collaboration avec Back Market, organise un MeetUp à Paris pour parler de DuckDB, MotherDuck et de tout ce qui concerne les données!
https://www.eventbrite.com/e/data-meetup-duckdb-traiter-les-donnees-a-vitesse-lumiere-motherduck-tickets-825278669717
Tu choisis le thème du prochain article.
A la semaine prochaine :)
