


Structurer sa donnée pour mieux l'analyser
#9 L'importance d'avoir des données tidy

Salut pour cette nouvelle édition.
Si tu me lis, tu dois sans doute faire parti des 181 privilégiés, merci ❤️
Si ce n’est pas déjà fait tu peux :
Découvrir un aperçu de mon livre QueryBook
Pour ne rater aucune publication :
Un petit Rappel avant de commencer

Pour quantifier l’impact de production sur l’environnement, on mesure les émissions de carbone selon 3 scopes.
Scope 1 : Émissions résultant de la combustion de carburants dans les processus industriels.
Scope 2 : Émissions provenant de la production d'électricité générée par des centrales électriques qui alimentent les bâtiments et les équipements de l'entreprise.
Scope 3 : Émissions découlant de la chaîne d'approvisionnement et du cycle de vie des produits. Ces émissions sont le résultat des activités de l'entreprise mais proviennent de sources non contrôlées directement par elle.

Contexte
En tant que data analyst RSE spécialisé dans la mesure des émissions de CO2 (dioxyde de carbone), mon rôle consiste à recueillir et structurer les informations transmises par les fournisseurs concernant leurs procédés de fabrication de contenants en verre. Ces données permettent d’évaluer l'efficacité des stratégies de réduction des émissions et de suivre leurs progrès au fil du temps. J'ai rapidement pris conscience de l'importance de mon rôle lorsque j’ai vu le diagramme ci-dessous pour la première fois.

Comme tu peux le constater, chez mon client actuel, les émissions de Scope 1 et 2 représentent moins de 20% du total des émissions de CO2 . En comparaison, la production de contenants en verre dans le Scope 3 compte à elle seule pour plus de 30% des émissions.
L'importance de structurer les données
La structuration de ces données est essentielle pour 2 raisons principales. Premièrement, elle aide à mesurer les progrès accomplis vers les objectifs de réduction des émissions de carbone. Oui, les émissions de CO2 des fournisseurs sont également comptabilisées dans le bilan carbone global de mon client.
Deuxièmement, ces informations améliorent notre évaluation des fournisseurs lors des appels d'offres, en tenant compte non seulement de leur capacité logistique, du coût et de la capacité de production, mais aussi de leur empreinte carbone (la quantité de gaz à effet de serre produite), que ce soit dans la fabrication des bouteilles ou leur transport.
Cette approche permet de choisir les fournisseurs non seulement sur la base du prix et de la qualité, mais aussi selon leur performance environnementale, renforçant ainsi notre engagement envers une responsabilité sociale et environnementale.
Pourquoi je raconte tout cela?
L'analyse de données n'est pas qu'une affaire de chiffres, c'est une démarche stratégique qui nécessite de comprendre pourquoi et comment les données sont manipulées. C'est en saisissant le but final que nous choisissons les données et que nous pouvons produire des analyses pertinentes qui aident véritablement l'entreprise à atteindre ses objectifs de développement durable.
La Transformation des Données pour une Meilleure Analyse
Dans la pratique, les données que nous recevons ne sont pas prêtes à l'emploi. Elles arrivent sous forme de formulaire avec un format large.
Pour un data analyst souhaitant utiliser cette donnée dans le but de créer des dashboards, ce format n'est pas idéal. Il nous faut des données "tidy" – propres et organisées selon 3 règles simples :
Chaque observation doit être sur une ligne distincte.

Chaque variable doit avoir sa propre colonne.

Chaque valeur doit occuper une seule cellule.
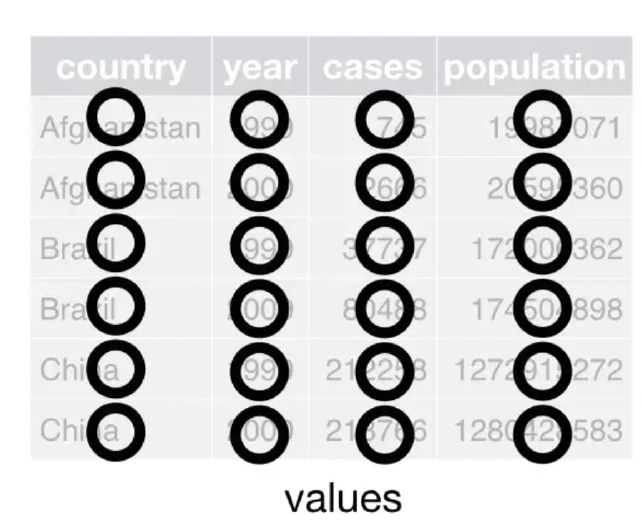
Exemple de Nettoyage des Données
Prenons un exemple concret. Dans le dataset suivant, nous avons la quantité de bouteilles en verre vendues selon l’année et le type de verre.

Est-ce que le jeu de données est tidy?
Non, regardons ensemble les différents problèmes.

La règle 1 n'est pas respectée : les ventes de bouteilles en flint de 2021 et celles de 2022 devraient chacune constituer une observation distincte. Cependant, elles sont actuellement regroupées sur la même ligne.
La règle 2 n'est pas suivie correctement. Les années 2021, 2022 et 2023, bien qu'étant des instances de la même variable temporelle, sont réparties sur trois colonnes distinctes alors qu'elles devraient être consolidées dans une seule colonne.

La règle 3, chaque valeur doit occuper une cellule. Pourtant “Flint - EU” représente 2 valeurs dans une cellule, il faut séparer le type de verre et la zone géographique.
Passons maintenant à la transformation de notre jeu de données pour le rendre conforme aux principes d'une structure tidy. Pour commencer, nous allons nous assurer que chaque valeur est isolée dans sa propre cellule en introduisant une colonne dédiée à la zone géographique.

Ensuite, chaque variable doit être représenté par une colonne unique. Pour cela, les intitulés de colonnes 2021, 2022 et 2023 sont transformés en une seule variable « année », et les valeurs de ces colonnes sont regroupées dans une nouvelle colonne intitulée « nb_bouteille » (nombre de bouteilles).

Grâce à ces ajustements, le jeu de données devient tidy et aisément exploitable dans d’autres outils. Avec ces données désormais structurées, l’utilisation d’outils de BI tels que PowerBI s’en trouve simplifiée. Partager ces informations organisées avec d’autres équipes facilite également la création de dashboards et de tableaux croisés dynamiques. La transformation de données brutes en insights stratégiques nécessite ces étapes essentielles de structuration des données.
A Revoir
Jeudi 18 Avril, Natacha et Julia et moi avons organisé un meetup chez Hymaïa.
➡ Comment créer du data storytelling en entreprise, Kevin
➡ Avantages des graphiques interactifs pour le data storytelling, Julia
➡ Les 7 pièges à éviter pour mener des analyses statistiques de qualité, Natacha
Pour revoir le live c’est ici ⬇️
C’est tout pour cette semaine, passe une excellente journée :)
